이번 시간에는 카프카 컨슈머의 커밋과 오프셋을 어떻게 관리를 하는지에 대해 알아본다. 카프카가 다른 큐 솔루션과 차별화되는 특징은 하나의 토픽에 대해서 여러 용도로 사용할 수 있다는 점이다. 일반적인 큐 솔루션은 특정 컨슈머가 데이터를 가져가게 되면 큐에서 삭제되어 다른 컨슈머가 데이터를 가져갈 수 없는데 카프카는 오프셋이라는 개념을 사용하여 여러 컨슈머가 토픽에서 메시지를 가져올 수 있도록 구현하였다.

카프카 개념 정리(6) - 카프카 컨슈머의 커밋과 오프셋 관리
커밋과 오프셋 관리
커밋과 오프셋 컨슈머가 poll()이라는 함수를 호출할 때 카프카에 저장되어 있는 메시지를 읽어오게 된다. 여기서 중요한 것은 어떤 과정을 통해서 데이터를 가져오는지에 대해서 알아야한다. 먼저 컨슈머 그룹의 컨슈머들은 각각의 파티션에 대해서 자신이 가져간 메시지의 위치 정보를 기록하고 있다. 바로 이 위치 정보가 오프셋이다. 그리고 이러한 위치 정보인 오프셋을 업데이트하는 것을 커밋이라고 한다.
컨슈머 그룹과 그룹에 할당되어 있는 컨슈머들이 많다면 이러한 위치 정보를 저장해야 할 공간이 필요할 것이다. 바로 이 공간을 카프카 내에 별도로 사용하는 토픽을 만들어서 오프셋 정보를 저장하여 관리한다.

컨슈머 그룹내에서 컨슈머 하나가 다운되는 겅우 리벨런스가 되는데 이 과정에서 메시지를 가져오지 않고 일시정지 후 다시 메시지를 가져올 때 최근 커밋된 오프셋부터 읽어서 가져오게 된다. 이 상황에서 경우의 수가 총 3가지가 발생할 수 있다.
1. 실제로 마지막으로 처리한 오프셋보다 저장되어 있는 오프셋이 작다면 메시지의 중복 처리 문제가 발생하게 된다.
2. 실제로 마지막으로 처리한 오프셋보다 저장되어 있는 오프셋이 크다면 그 차이만큼의 오프셋에 저장되어 있는 데이터가 누락된다.
3. 마지막으로는 정상적인 경우이다.
이처럼 커밋은 매우 중요한 부분이며 카프카에서는 여러가지의 방법이 제공된다. 자동 커밋 방법과 수동 커밋 방법이 바로 그것이다.
자동 커밋
카프카에서 직접 오프셋을 관리하지 않는 자동 커밋 방법을 제공한다. 자동 커밋을 사용하고 싶은 경우에는 컨슈머 옵션 중 enable.auto.commit = true로 설정해주면 컨슈머에서 poll()을 호출할 때 가장 마지막 오프셋을 자동으로 커밋한다. 해당 옵션은 아래에 나와 있듯이 default 값이 true이다.

위에서 컨슈머에서 poll()을 호출하는데 해당 함수를 호출하는 간격을 설정할 수 있으며 기본값은 5초이다. 즉 5초마다 컨슈머가 poll()을 호출하고 오프셋을 커밋한다는 의미이다. 해당 설정은 auto.commit.interval.ms 옵션을 통해 설정이 가능하다.

해당 옵션 외에도 다른 옵션들을 아래 kafka 공식 홈페이지에서 참고가 가능하다.
https://kafka.apache.org/documentation/#brokerconfigs
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
다음 사진은 자동 커밋 설정일 때 일반적인 상황에 대한 사진이다. 현재 5초마다 자동 커밋이 이루지며 컨슈머가 poll()을 통해 메시지를 가지고가고 있다.
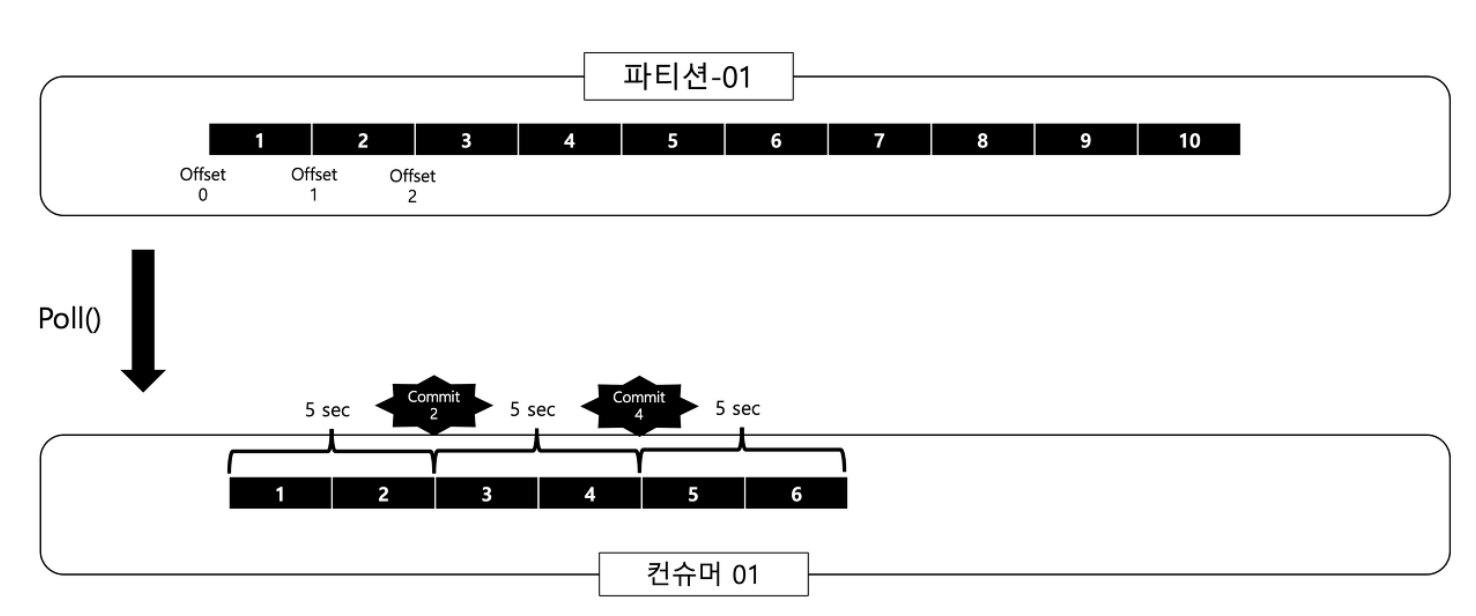
위에 사진은 일반적으로 문제가 없이 진행되는 상황에서의 예이고 다음 사진은 컨슈머가 리벨런스되는 상황에서의 예이다. 사진을 보면 3,4 까지는 제대로 가지고 와서 커밋이 이루어졌다. 그다음 컨슈머에서는 5,6을 가지고 왔는데 커밋이 이루어지기 전에 리벨런스가 되는 상황이 나타났다. 그렇게 리벨런싱 된 컨슈머 02에서는 다시 5,6을 가지고 와서 메시지를 중복으로 처리하게 되는 경우가 생긴다. 이러한 이유는 5,6에서 커밋을 하기 전에 리벨런스가 됐기 때문이다.
단순히 이러한 상황에서 자동커밋하는 주기인 5초라는 시간을 줄여 더 짧은 주기로 커밋을 하게 되면 어느정도 중복이 되는 경우는 줄어들겠지만 완벽하게 중복을 제거하는 것은 불가능하다. 자동 커밋의 편리한 점이 있지만 중복이 될 수 있다는 점을 이해하고 사용하는 것이 좋다.
수동 커밋
수동 커밋은 메시지 처리가 완료될 때까지 메시지를 가져온 것으로 간주되어서는 안되는 경우에 사용한다. 이 말을 좀 더 이해하기 쉽게 상황으로 설명하면 컨슈머가 가지고 온 메시지를 디비에 저장한다고 했을 때 해당 메시지가 디비에 저장 된 후에 커밋이 진행되어야 한다.
만약 그 이전에 커밋이 된 상태에서 컨슈머에 장애가 발생하게 되면 해당 메시지들이 손실 될 수 있는 상황이 발생한다. 그리고 그 반대로 가져온 메시지를 디비에서 저장하는 도중에 실패하게 된다면 일부 메시지들이 중복이 되는 상황도 발생할 수 있다.
이렇듯 수동 커밋을 사용하면 설정해줘야 하는 것은 늘어나겠지만 메시지를 가져온 것으로 간주되는 시점을 조정이 가능하므로 메시지의 손실과 중복과 같은 상황을 방지할 수 있다는 장점이 있다.
지난 글
카프카 개념 정리(5) - 파티션 할당과 리더와 팔로워 선출 ISR
카프카 개념 정리(5) - 파티션 할당과 리더와 팔로워 선출 ISR
이번 시간에는 컨슈머와 파티션의 개수의 따른 할당 케이스와 그 과정에서 리더와 팔로워를 왜 선출하고 어떤 방식으로 선출되어 사용되는지 정리한다. 추가적으로 ISR(In Sync Replica)에 대한 개념
sjparkk-dev1og.tistory.com
카프카 개념 정리(4) - 카프카는 데이터를 어떻게 저장하고 읽어오는가?
카프카 개념 정리(4) - 카프카는 데이터를 어떻게 저장하고 읽어오는가?
이번 시간에는 카프카에서 데이터를 어떻게 저장하고 읽어오는지에 대해서 정리한다. 카프카 개념 정리(4) - 카프카는 데이터를 어떻게 저장하고 읽어오는가? 데이터를 어떻게 저장하는가? 카프
sjparkk-dev1og.tistory.com
카프카 개념 정리(3) - 카프카 아키텍처
이번 시간에는 카프카에 대해서 좀 더 자세히 알아보는 시간을 가진다. 카프카의 아키텍처에 대해서 이해해본다. 카프카가 어떠한 구조로 이루어져있고 각 구조들이 어떠한 역할을 하는지에 대
sjparkk-dev1og.tistory.com
카프카 개념 정리(2) - 카프카의 동작 방식 Pub Sub
카프카 개념 정리(2) - 카프카의 동작 방식 Pub Sub
카프카에 대한 개념을 정리하는 시간을 가지려 한다. 그 두번째로 카프카의 동작 방식과 pub / sub 모델의 대한 장단점과 특징 및 메시징 시스템이란 무엇인지에 대해서 정리한다. 카프카 개념 정
sjparkk-dev1og.tistory.com
카프카 개념 정리(1) - 카프카와 카프카의 탄생 배경
카프카에 대한 개념을 정리하는 시간을 가지려 한다. 그 첫번째로 카프카가 무엇인지 간단한 개념과 카프카가 탄생하게 된 배경에 대해서 정리한다. 카프카에 대한 자세한 설명은 (2)에서 정리
sjparkk-dev1og.tistory.com
참고
https://firststep-de.tistory.com/41
[Apache Kafka] 카프카 컨슈머의 커밋(commit)과 오프셋(offset)을 알아보자 [4]
이번 포스팅을 통해서 컨슈머의 커밋과 오프셋에 대해서 알아보도록 하겠습니다. 카프카가 다른 메시지 큐 솔류션과 차별화되는 특징은 하나의 토픽에 대해 여러 용도로 사용할 수 있다는 점입
firststep-de.tistory.com
https://kafka.apache.org/documentation/#brokerconfigs
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
'Kafka' 카테고리의 다른 글
| 카프카 개념 정리(5) - 파티션 할당과 리더와 팔로워 선출 ISR (0) | 2022.12.31 |
|---|---|
| 카프카 개념 정리(4) - 카프카는 데이터를 어떻게 저장하고 읽어오는가? (0) | 2022.12.28 |
| 카프카 개념 정리(3) - 카프카 아키텍처 (0) | 2022.12.25 |
| 카프카 개념 정리(2) - 카프카의 동작 방식 Pub Sub (0) | 2022.12.22 |
| 카프카 개념 정리(1) - 카프카와 카프카의 탄생 배경 (0) | 2022.12.19 |




댓글