이번 시간에는 카프카에서 데이터를 어떻게 저장하고 읽어오는지에 대해서 정리한다.

카프카 개념 정리(4) - 카프카는 데이터를 어떻게 저장하고 읽어오는가?
데이터를 어떻게 저장하는가?
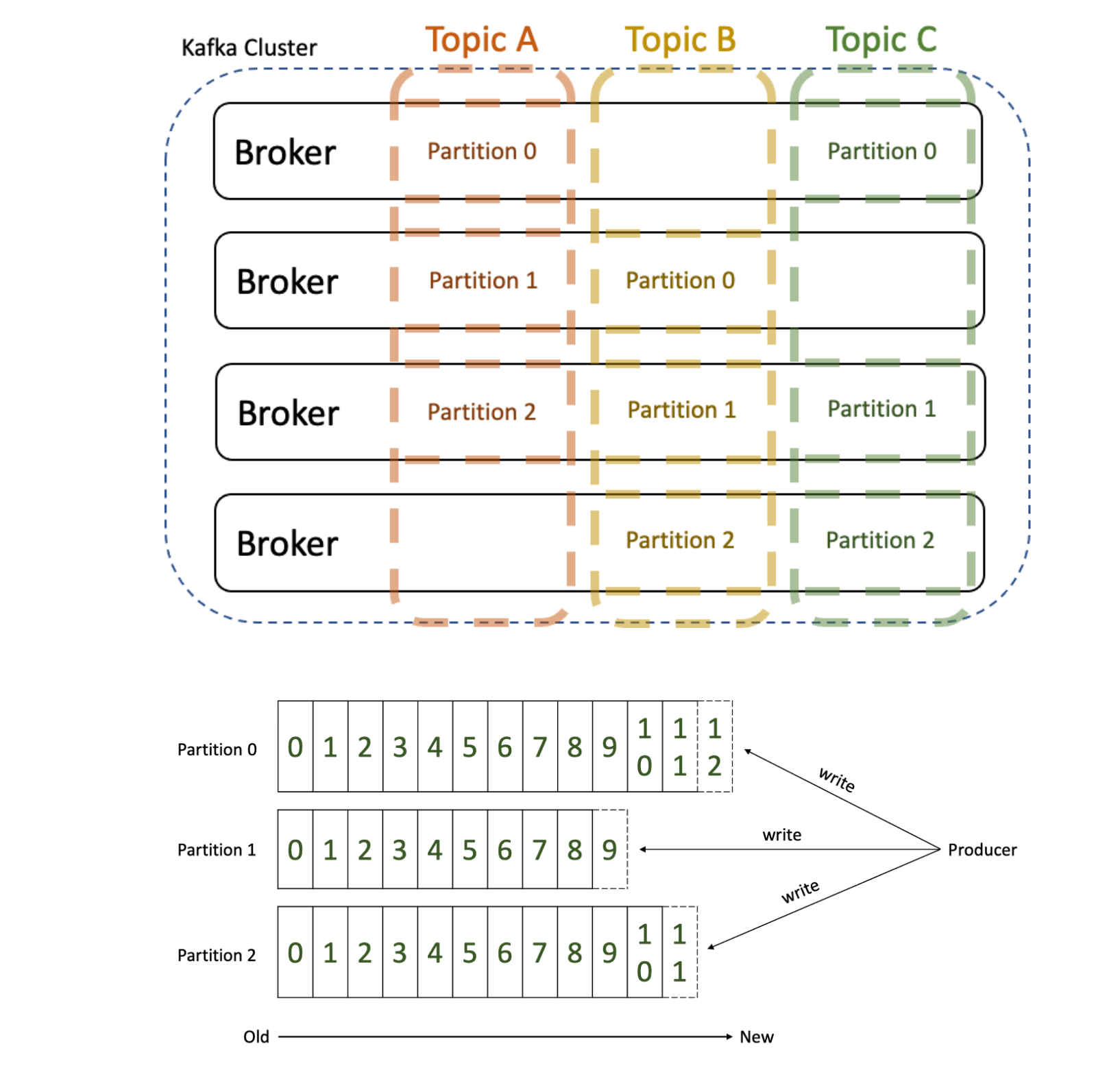
카프카에서는 데이터를 구분하기 위한 단위로 토픽이라는 용어를 사용하고 이곳에 데이터를 저장한다. 토픽의 이름은 249자 미만의 영문, 숫자, . , _ , - 를 조합하여 만들 수 있으며 여러 서비스에서 공통으로 카프카 클러스터를 사용하게 된다면 토픽명으로 구분을 주는 것이 좋다.
그리고 각 토픽은 1개 이상의 파티션으로 나뉘어지며 프로듀서가 보낸 메시지를 파티션에 분산하여 저장하게 된다. 파티면 마다 메시지가 저장되는 위치를 오프셋이라고 한다. 오프셋의 특징으로는 파티션 내에서 유일하고 순차적으로 증가하는 숫자(정수) 형태로 되어 있다. 이러한 오프셋을 통해 파티션 내의 메시지 순서를 보장한다.
데이터를 어떻게 읽어오는가?

컨슈머들은 하나 이상의 토픽에서 메시지들을 가지고 올 수 있으며 메시지가 토픽에 들어오면 자동으로 해당 메시지를 가지고 온다.
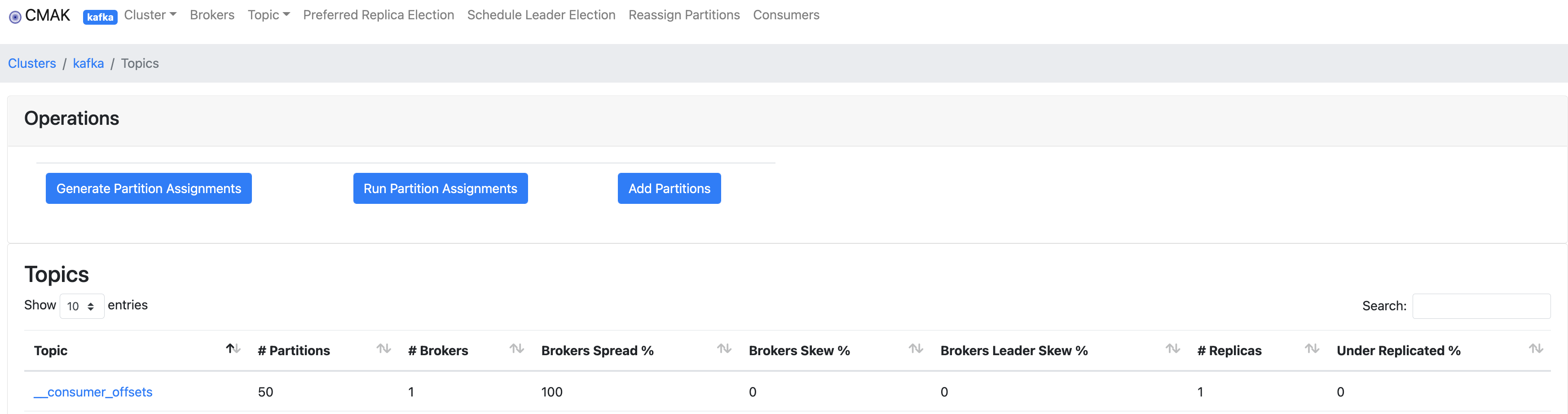
컨슈머들은 오프셋 순서대로 데이터를 가지고 온다. 혹시나 가지고 오는 도중에 장애가 발생하여 서버가 다운되는 경우를 대비하여 컨슈머들은 자신의 오프셋 정보를 특수한 토픽(__consumer_offsets)에 저장한다.
해당 사진은 CMAK 구성 후 접속하면 확인이 가능하다. 토픽 리스트에서 __consumer_offsets을 확인할 수 있다.
그리고 각 컨슈머 그룹들은 1개 이상의 컨슈머들로 구성되어 있고 고유한 ID를 가진다 (여기서 ID는 Consumer Group ID) 컨슈머 그룹의 컨튜머들은 파티션 단위로 각 토픽의 데이터를 병렬로 분산하여 처리한다.
지난 글
카프카 개념 정리(3) - 카프카 아키텍처
이번 시간에는 카프카에 대해서 좀 더 자세히 알아보는 시간을 가진다. 카프카의 아키텍처에 대해서 이해해본다. 카프카가 어떠한 구조로 이루어져있고 각 구조들이 어떠한 역할을 하는지에 대
sjparkk-dev1og.tistory.com
카프카 개념 정리(2) - 카프카의 동작 방식 Pub Sub
카프카에 대한 개념을 정리하는 시간을 가지려 한다. 그 두번째로 카프카의 동작 방식과 pub / sub 모델의 대한 장단점과 특징 및 메시징 시스템이란 무엇인지에 대해서 정리한다. 카프카 개념 정
sjparkk-dev1og.tistory.com
카프카 개념 정리(1) - 카프카와 카프카의 탄생 배경
카프카 개념 정리(1) - 카프카와 카프카의 탄생 배경
카프카에 대한 개념을 정리하는 시간을 가지려 한다. 그 첫번째로 카프카가 무엇인지 간단한 개념과 카프카가 탄생하게 된 배경에 대해서 정리한다. 카프카에 대한 자세한 설명은 (2)에서 정리
sjparkk-dev1og.tistory.com
참고
https://damdam-kim.tistory.com/16
Apache Kafka 개요 & Architecture 설명
목차 Apache Kafka Kafka Architecture Kafka 데이터 쓰기 Kafka 데이터 읽기 Apache Kafka LinkedIn에서 최초로 출발하여 정식 Apache Opensource로 등록된 분산 이벤트 스트리밍 플랫폼 Producer와 Consumer의 분리 (Pub / Sub
damdam-kim.tistory.com
'Kafka' 카테고리의 다른 글
| 카프카 개념 정리(6) - 카프카 컨슈머의 커밋과 오프셋 관리 (0) | 2023.01.08 |
|---|---|
| 카프카 개념 정리(5) - 파티션 할당과 리더와 팔로워 선출 ISR (0) | 2022.12.31 |
| 카프카 개념 정리(3) - 카프카 아키텍처 (0) | 2022.12.25 |
| 카프카 개념 정리(2) - 카프카의 동작 방식 Pub Sub (0) | 2022.12.22 |
| 카프카 개념 정리(1) - 카프카와 카프카의 탄생 배경 (0) | 2022.12.19 |




댓글