기사 추천 알고리즘을 만들기 위해 이용할 수 있는 구글에 Natural Language API에 대한 내용을 정리하고, 구현한 코드와 데모사이트에서 제공하는 결과 값을 비교한 내용을 정리한다.

Google - Natural Language API
구글이 제공하는 Natural Language AI에는 머신러닝 커스텀 모델을 학습하여 사용할 수 있는 AutoML 기능과 자연어 이해를 적용할 수 있는 Natural Language API 기능을 제공한다.
Natural Language API 와 AutoML
Natural Language API는 강력한 선행 학습된 모델을 통해 감정 분석, 항목 분석, 구문 분석, 콘텐츠 분류의 기능을 통해 개발자가 애플리케이션에 자연어 이해를 쉽게 적용시킬 수 있도록 지원한다.
AutoML은 구글에서 제공하는 머신러닝 기능으로 AutoML에 기반한 자연오용 Vertex AI를 사용하면 최소한의 수고와 머신러닝 지식만으로 감정을 분류하거나 추출, 인식하도록 하는 고품질의 커스텀 머신러닝 모델을 학습시킬 수 있다. AutoML UI를 사용하게 되면 코드를 작성하지 않고도 학습 데이터를 업로드하고 커스텀 모델을 테스트 할 수 있다.
Natural Language API & AutoML 비교
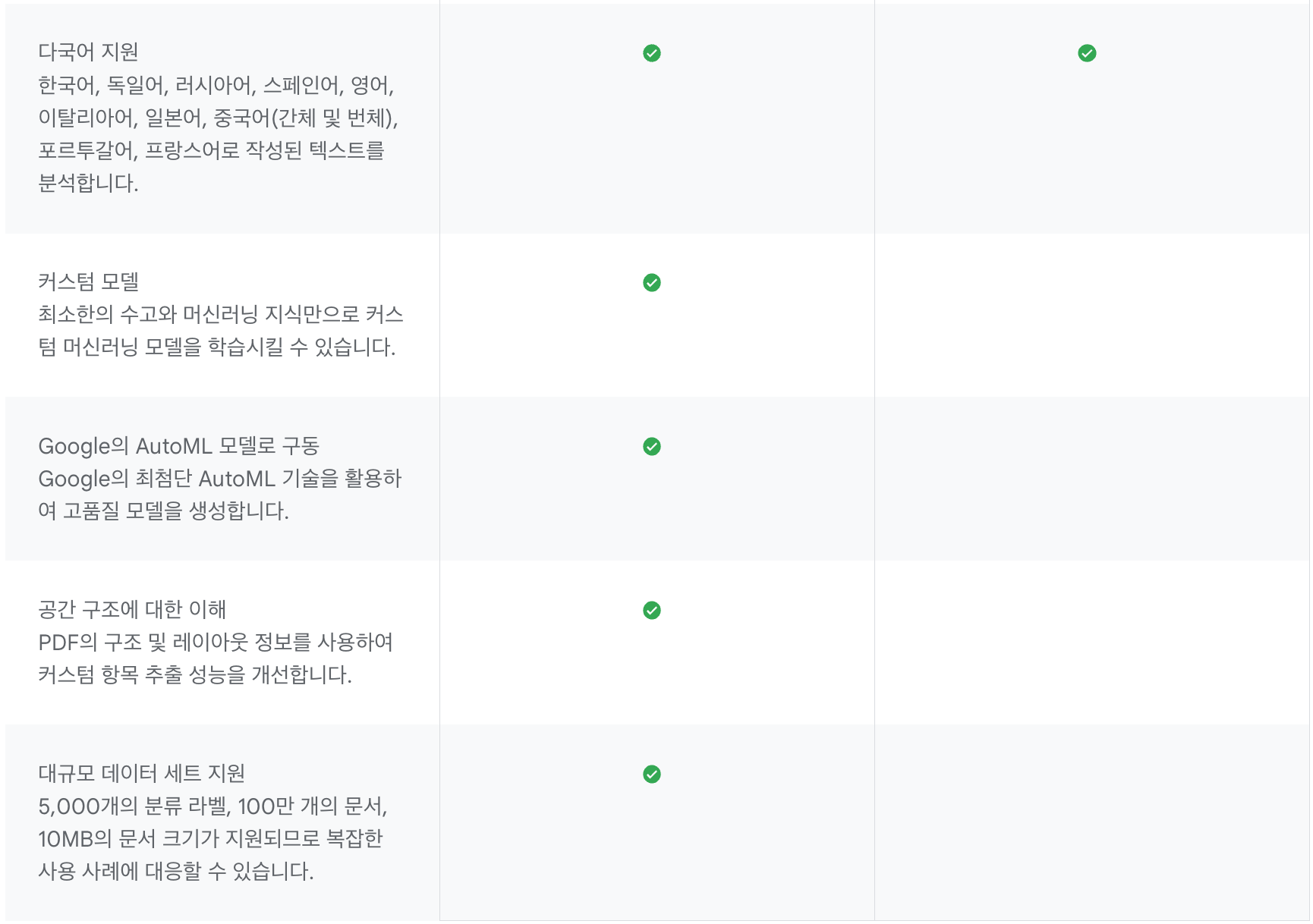
아래 표를 통해 Natural Language API 와 AutoML의 차이점을 한눈에 확인이 가능하다. 둘 다 REST API를 제공하며 Cloud Storage를 사용할 수 있으며, 구문 분석, 항목분석, 감정분석, 콘텐츠 분류 모두 사용이 가능하다.
다만 차이점이라면 AutoML의 경우 사용자가 커스텀하게 머신러닝 모델을 학습시켜 원하는 대로 구성을 할 수 있는 것이며, Natural Language API에 경우는 구글에서 이미 학습 시킨 모델을 기반으로 데이터를 제공한다는 차이점이 있다.
Natural Language API를 사용하면 수천 개의 선행 학습된 분류를 통해 텍스트의 구조와 의미를 파악할 수 있고, AutoML을 사용하면 구체적인 요구사항에 맞는 커스텀 카테고리로 콘텐츠를 분류할 수도 있다.

Natural Language API
Natural Language API에 대해서 자세히 알아본다. 아래 구글이 제공하는 데모사이트를 통해서 손쉽게 테스트가 가능하며 기능별로 결과 확인이 가능하다. 추가적으로 테스트를 하다가보면 한글에 대한 컨텐츠 분류가 안되는 상황이 발생하는데 해당 케이스에 해결방법도 정리한다.
https://cloud.google.com/natural-language?hl=ko#section-2
Cloud Natural Language | Google Cloud
선행 학습된 API나 커스텀 AutoML 머신러닝 모델을 사용한 AI로 텍스트를 분석해 관련 항목을 추출하고 감정 등을 파악하세요.
cloud.google.com
먼저 Natural Language API에서 제공되는 기능으로는 크게 4가지가 있다.
- 감정 분석
- 항목 분석
- 구문 분석
- 콘텐츠 분류 (카테고리)
데모사이트에 접속하면 다음과 같은 화면을 찾을 수 있다. 이미 미리 내용이 적혀 있고 ANALYZE 버튼을 통해서 분석이 가능하다.

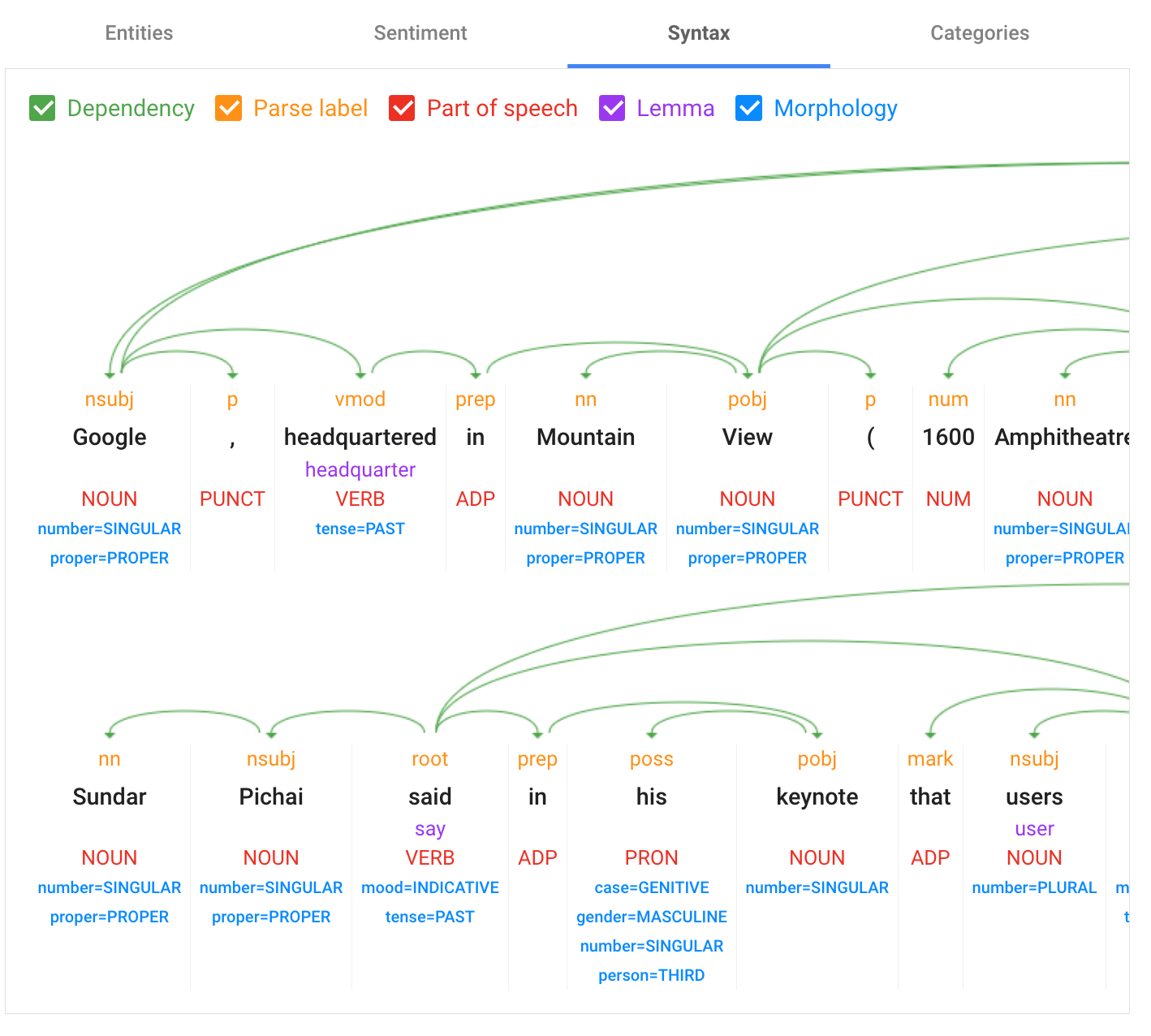
분석 버튼을 누르면 총 4가지 항목에 대해서 다음과 같이 결과를 보여준다.

4가지 항목의 결과는 다음과 같다.
왼쪽 위부터 항목분석, 감정분석, 구문분석, 컨텐츠 분류 순이다.


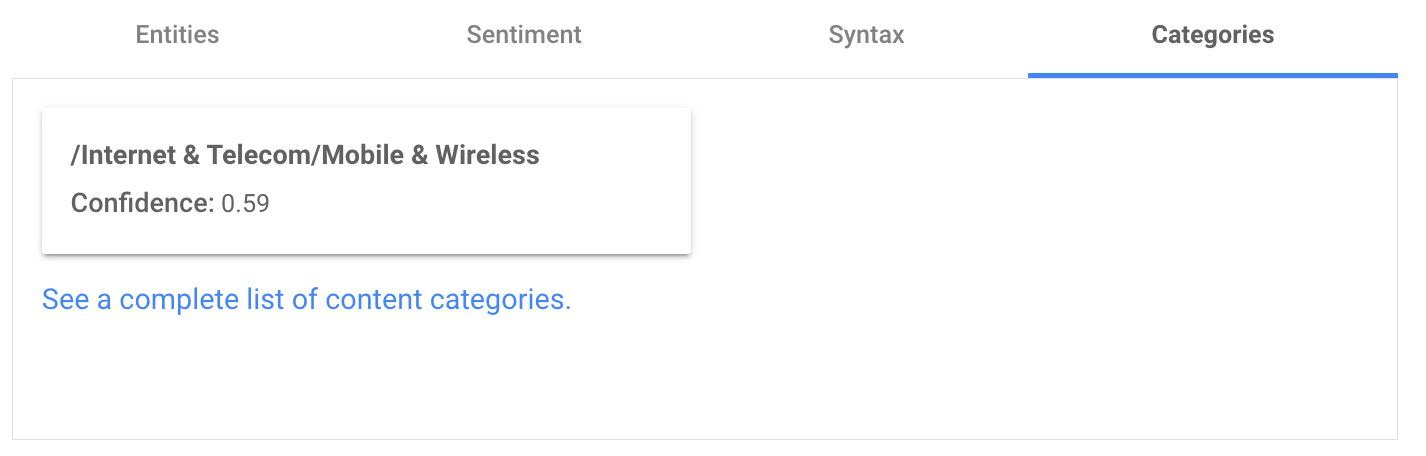
이번에는 영어가 아닌 한국어로 같은 내용을 분석한 결과다.
전반적으로 잘 동작이 되는거 같지만 자세히 보면 맨 마지막 기능이 컨텐츠 분류 결과값이 나오지 않는 것을 확인할 수 있다.




내용을 확인해보면 지원하지 않는 언어라는 내용이다. 여기까지만 보면 한국어를 제공하지 않는 것처럼 생각할 수 있다. 하지만 그럴리가 없으니 문서를 찾아보았다.
하지만 그럴리가 없으니 문서를 찾아보았다. 구글의 문서를 찾아보면서 느낀건데 문서들은 참 많은데 너무 많아서 찾기가 좀 힘든점이 없지 않아 있었다. 그래도 없는 것보단 나으니 다음 내용을 확인해보자.
콘텐츠 분류 기능에는 V1 model과 V2 model이 존재한다고 한다. 해당 내용에서는 V2 모델의 성능이 더 우수하다는 정도의 내용과 예시 정도만 보여준다.

콘텐츠 분류와 관련된 문서들을 확인하다보면 아래와 같이 언어 지원에 대한 내용이 있어서 확인해보니 여기에 해답이 있었다.

다음과 같이 V2 모델에서만 여러 언어에 대해서 기능을 제공하고 V1 모델은 영어만 지원하는 것을 확인할 수 있다. 바로 이런점이 문서가 너무 많아 보기 힘들다고 한점이다. 해당 내용은 처음에 컨텐츠 분류 탭에 같이 넣어주면 바로 확인이 가능한 것인데 돌고 돌아 찾았다.

자 그럼 여기서 알 수 있는 것은 데모사이트에서는 V1 모델을 사용한 컨텐츠 분류 API를 사용하기 때문에 한국어로 된 내용에 대해서 기능을 지원 안했다는 사실을 알 수 있다.
자 그럼 V2 모델을 사용해서 컨텐츠 분류 기능을 사용하면 잘 분류를 해주는지 확인해보자
V2 모델과 V1 모델 컨텐츠 분류 비교
컨텐츠 분류 기능을 사용할 기사는 다음과 같다.
한창섭 행정안전부 차관(장관 직무대행)은 15일 주재한 코로나19 중앙재난안전대책본부 회의에서
“정부는 20일부터 버스·전철 등 대중교통과 마트·역사 등 대형시설 안의 개방형 약국에 대해서도
마스크 착용 의무를 추가로 해제한다”고 밝혔다. 마스크 착용 의무 추가 해제는 1월 말 실내마스크
착용 의무 해제 이후 코로나19 상황이 안정적으로 관리되고 있다고 판단했기 때문이다.
한 차관은 “지난 1월 30일 실내마스크 착용 의무 조정 이후 일 평균 확진자는 38% 신규 위중증
환자는 55% 감소했다”며 “신규 변이도 발생하지 않는 등 방역 상황은 안정적인 것으로 판단된다”고 설명했다.
Vice Minister of Public Administration and Security Han Chang-seop (acting minister) held a meeting of the COVID-19 Central Disaster and Safety Countermeasures Headquarters on the 15th
"From the 20th, the government will also discuss public transportation such as buses and trains, as well as open pharmacies in large facilities such as marts and stations."
"We will further lift the obligation to wear masks," he said. The additional cancellation of the obligation to wear a mask is an indoor mask at the end of January
This is because it was judged that the COVID-19 situation was being managed stably after the lifting of the wearing obligation.
Vice Minister Han said, "Since the adjustment of the obligation to wear indoor masks on January 30, the average daily number of confirmed patients has been 38% of new critical conditions
The number of patients decreased by 55%, he said. "The quarantine situation is judged to be stable, with no new mutations occurring."
먼저 영어 V1 모델을 사용하여 컨텐츠 분류 기능을 사용하면 다음과 같은 결과를 얻을 수 있다.

다음은 V2 모델로 구현한 코드에서 같은 내용의 기사를 한국어로 추출했을 때의 결과 값이다.

같은 내용인데도 훨씬 더 많은 콘텐츠 분류 값을 알려준다. 위에서도 말했듯이 V2 모델이 성능이 더 우수하다고 하는 것이 이런 점을 말하는 것 같다.
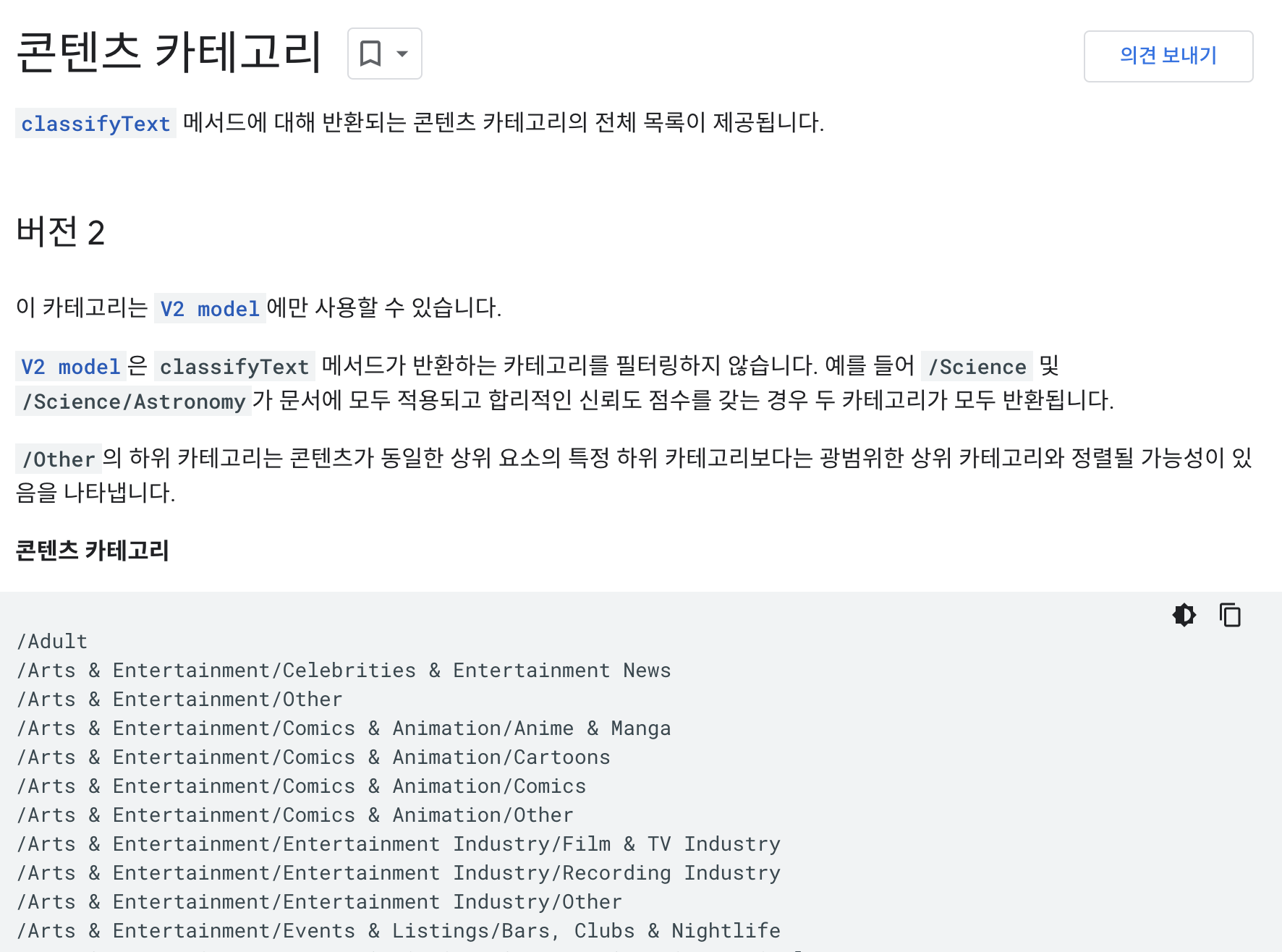
또 문서를 뒤적뒤적하다보면 다음과 같은 내용을 찾을 수 있는데 여기서 버전2와 버전1에서 제공하는 콘텐츠 카테고리의 전체 정보를 확인할 수 있다.
참고
언어 지원
https://cloud.google.com/natural-language/docs/languages?hl=ko
언어 지원 | Cloud Natural Language API | Google Cloud
의견 보내기 언어 지원 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Cloud Natural Language API에서는 다양한 언어를 지원합니다. 요청 내에서 language 매개변수
cloud.google.com
콘텐츠 카테고리
https://cloud.google.com/natural-language/docs/categories?hl=ko
콘텐츠 카테고리 | Cloud Natural Language API | Google Cloud
의견 보내기 콘텐츠 카테고리 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. classifyText 메서드에 대해 반환되는 콘텐츠 카테고리의 전체 목록이 제공됩니다
cloud.google.com
'개발지식' 카테고리의 다른 글
| 텔레그램 봇을 이용한 알림 서비스 만들기(1) (1) | 2023.04.09 |
|---|---|
| 동시성 이슈를 해결하기 위한 Redisson 분산락 알아보기(1) (0) | 2023.03.27 |
| imageMagick 을 활용한 이미지 확장자 및 사이즈 변환 (0) | 2023.01.13 |
| 아파치와 톰캣 및 WAS와 WebServer (0) | 2022.09.15 |
| iTerm을 이용한 AWS EC2 SSH 접속 Profile 만드는 방법 (0) | 2022.05.27 |




댓글